들어가며
2024년 말까지 기간계파트를 담당하면서 한샘몰의 메모리 누수 및 OOM 이슈는 DevOps 파트에서 전해들어 인지하고 있었지만, 해당 이슈에 대해 별다른 대응은 하지 않고 있었습니다. 2025년이 되어 웹 성능 개선 파트를 리딩하게 되면서 몰 코드를 전반적으로 살펴보게 되었고, 디자인시스템, 전시 컴포넌트 시스템, 한샘몰 코드 베이스까지 모든 C사이드(Customer Side)의 코드를 분석하게 되었습니다. 특히 토스 이벤트가 트리거가 되어 기존 한샘몰의 메모리 누수 이슈가 부각되면서 자연스럽게 업무가 할당되었습니다. 이 글은 메모리 누수의 디버깅 과정과 해결 과정을 다루고 있습니다.
문제 상황
현상 파악
- 현상 1: 스토어웹 서비스의 모바일웹(모웹) MSA가 주기적으로 재기동되는 현상 발견
- 현상 2: 사용자 트래픽이 많은 이벤트 상황에서 재기동 주기가 더 짧아짐
- 현상 3: 평시에는 다수의 Pod가 번갈아가며 재기동되어 사용자 경험에 큰 영향이 없었으나, 이벤트 시에는 페이지 오류 노출이 빈번해짐
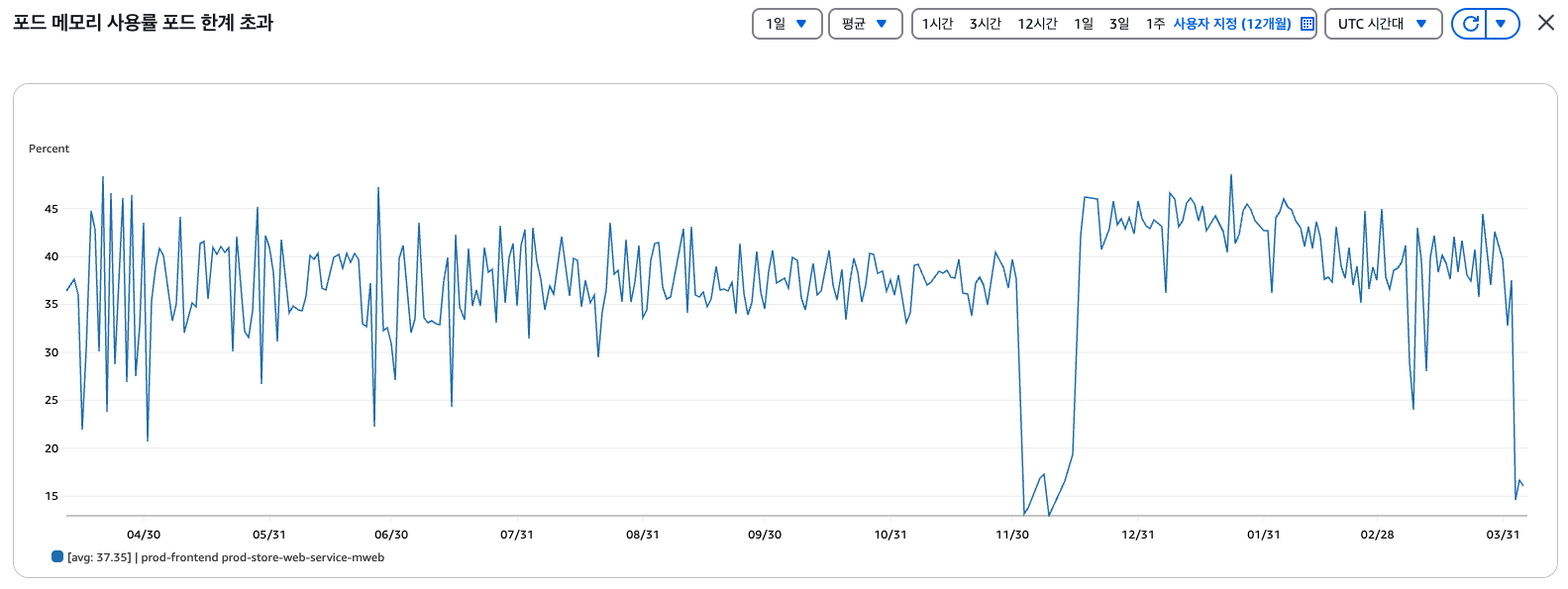
3월 중순 약 80만 사용자가 유입된 토스 이벤트에서 서비스가 중단되는 일이 발생했습니다. EKS 환경에서 BE의 Pod는 5대에서 60대, FE의 Pod는 15대에서 60대로 증설했고, FE Pod는 0.5core에서 1core, 4GB에서 6GB로 스케일업했지만 서비스 중단 현상이 계속되었습니다. 또한 IDC(기간계)와 AWS 간 통신 대역폭(500Mbps)이 포화되어 용량을 임시 증설해야 하는 상황까지 이어졌습니다.
그래프의 모양은 전형적인 메모리 누수 패턴을 보여주었습니다. 우상향하며 메모리 사용률이 증가하고, GC가 이루어지기 전에 OOM Kill이 발생하면서 Pod가 재기동되고, 메모리 사용률이 일시적으로 낮아지는 현상이 반복되었습니다.
트러블슈팅 과정
1. 서비스 아키텍처 분석 및 PM2 제거
가장 먼저 시도한 조치는 PM2 제거였습니다. PM2는 노드 프로세스를 관리하는 애플리케이션으로, 노드 서버의 병렬 구성 및 로드밸런싱 기능을 담당합니다. 이 아키텍처를 최초 설계했을 당시에는 VM(IDC 배포)를 고려했을 것으로 추측됩니다. 하지만 Kubernetes 환경에서는 PM2의 기능이 중복되고, 예상과 다른 동작을 보이는 등 여러 문제가 있었습니다:
-
PM2 서버 인스턴스 개수 오류:
- 모웹 Pod 리소스는 0.125C/1GB로 PM2 설정상 1개의 인스턴스가 기동되어야 하나 4개가 동작했습니다.
- PM2가 Pod의 Spec이 아닌 Node의 Spec(0.5C/4GB)을 참조하고 있는 것으로 보였습니다.
-
개발팀 직접 관리 영역 발생:
- PM2는 MSA 소스 코드에서 관리되기 때문에 개발자들이 직접 관리해야 했습니다
- 소스 레이어 외에 애플리케이션 및 플랫폼 레이어에 대한 학습이 필요했습니다.
-
DevOps에서 리소스 Control이 불가능한 구조:
- PM2에서 리소스 Control을 하려면 소스 코드 수정이 필요해 서비스 코드를 직접 보지 않고는 파악하기 어려웠습니다.
PM2 제거 후 테스트 결과
PM2를 제거한 후 스트레스 테스트와 부하 테스트를 진행했습니다:
- 스트레스 테스트: PM2 적용 환경(DEV)에서는 종료 코드 137(OOM Kill)이 발생했으나, PM2 제거 환경(PJ)에서는 종료 코드 143(Graceful Shutdown)으로 정상 종료 프로세스가 동작했습니다.
- 부하 테스트: PJ 환경에서는 Node가 Soft heap limit 50%를 유지했고, DEV 환경에서는 60~70%를 유지했지만 두 환경 모두 서비스는 정상적으로 유지되었습니다.
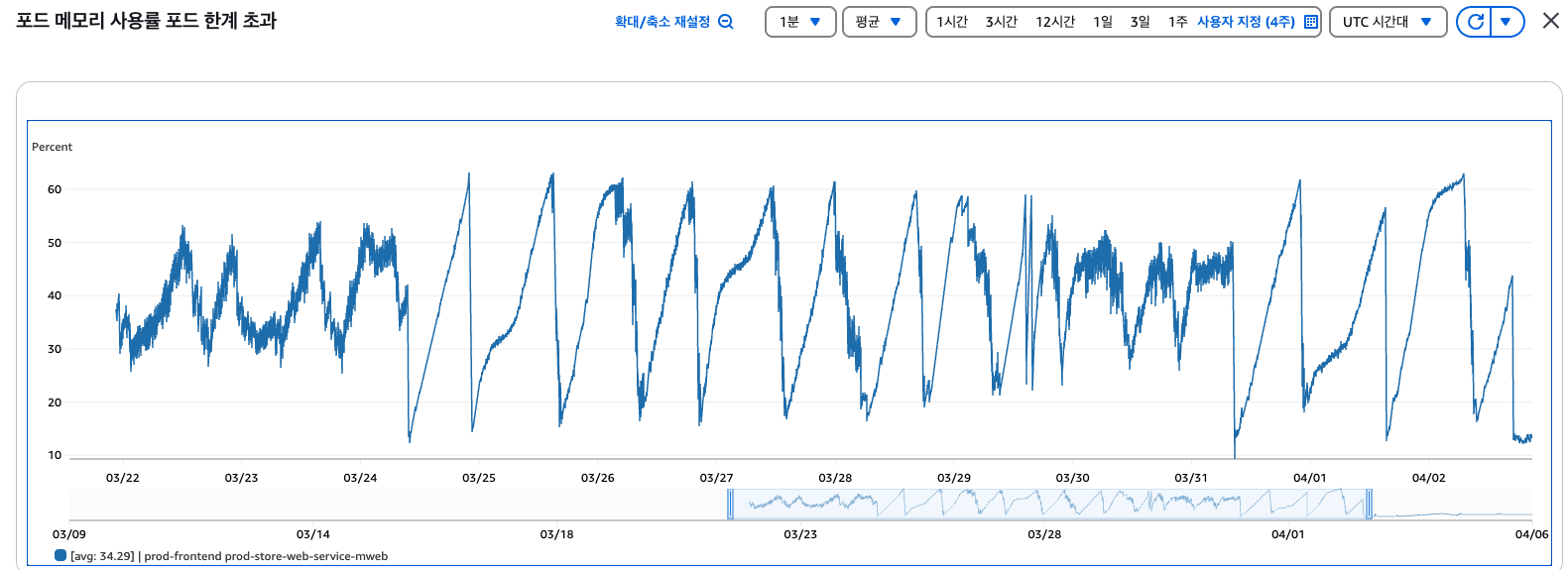
비정기 배포 후 모니터링 결과, 개발 환경에서 검증했던 형태의 그래프와 결과가 일치하지 않았습니다. 다만 종료 코드가 129로 변경되었는데, 이는 Hang Up Signal로 메모리가 임계치에 가까워지면서 Kernel에서 프로세스 헬스 체크 응답 지연으로 인한 프로세스 종료로 판단되었습니다.
2. Node Parameter 적용
Node.js 문서를 참고하여 다음과 같은 GC 관련 파라미터를 검토했습니다:
--max-old-space-size: Node의 Soft heap limit 변경 (기본값 50%)
PJ 환경에서 --max-old-space-size 값을 50%에서 70%로 변경하여 테스트했으며, 정상 적용되는 것을 확인했습니다. 하지만 이것이 Memory Leak에 영향을 줄 수 있을지는 명확하지 않았습니다.
3. STG 환경에서의 부하 테스트
개발 환경과 프로덕션 환경의 메모리 사용량 그래프가 크게 달랐기 때문에, 프로덕션 환경에만 적용된 코드나 기술이 있는지 확인했습니다. STG 환경을 기준으로 부하 테스트를 진행했으며, 테스트 기준은 상품 상세 페이지의 SSR 구간에서 받아오는 API 응답값 사이즈였습니다. 이 과정에서 API 응답값이 지나치게 큰 케이스가 있다는 것이 발견되었습니다.
- 2.18MB 크기의 NEXT_DATA가 있는 페이지: 테스트 수행 후 4-5분 사이에 서비스 재기동
- 0.0155MB 크기의 NEXT_DATA가 있는 페이지: 천천히 우상향하는 메모리 사용 패턴
이 테스트는 SSR 데이터 크기가 메모리 누수 및 OOM에 영향을 미치는지 파악하기 위한 것이었으며, 이 데이터가 프로덕션 및 STG 환경에만 적용된 Sentry와 연관성이 있는지 확인하기 위함이었습니다.
원인 및 해결책
원인 분석
한샘몰의 메모리 누수 원인은 다음과 같은 요소들이 복합적으로 작용한 것으로 판단됩니다:
-
PM2의 부적절한 사용:
- Kubernetes 환경에서 불필요한 오버헤드를 발생시켰습니다.
- Pod 리소스 할당 대비 과도한 프로세스가 생성되었습니다.
-
SSR 구간에서 Sentry 사용 시 매모리 누수:
- Sentry 적용 시 메모리 사용률이 증가하는 현상이 관찰되었습니다.
-
대용량 Server Response:
- 상품 상세 페이지의 SSR 시점에 응답 받은 데이터의 사이즈가 큰 경우(2.18MB) 서비스 재기동이 빠르게 발생했습니다.(메모리 누수의 가속화)
- 해당 데이터는 CMS에서 상품 상세 페이지를 구성할 때 Figma에서 export한 html 파일을 그대로 사용하는 부서가 있었기 때문에 발생한 것으로 파악되었습니다.
- 특정 상품에서 2MB가 넘는 figma 메타데이터 문자열이
<span>태그에 삽입되었고, 해당 문자열을 상품 페이지의 렌더와는 아무 연관이 없는 메타데이터에 불과했습니다. - 해당 데이터가 DB에 문자열로 저장되어 있다보니, IDC - AWS 대역폭(500MB)도 금방 소진되는 현상이 있었습니다. 결국 Figma의 메타데이터가 토스 이벤트 당시 DB, BE, FE에 모두 영향을 미치는 요소로 작용했습니다.
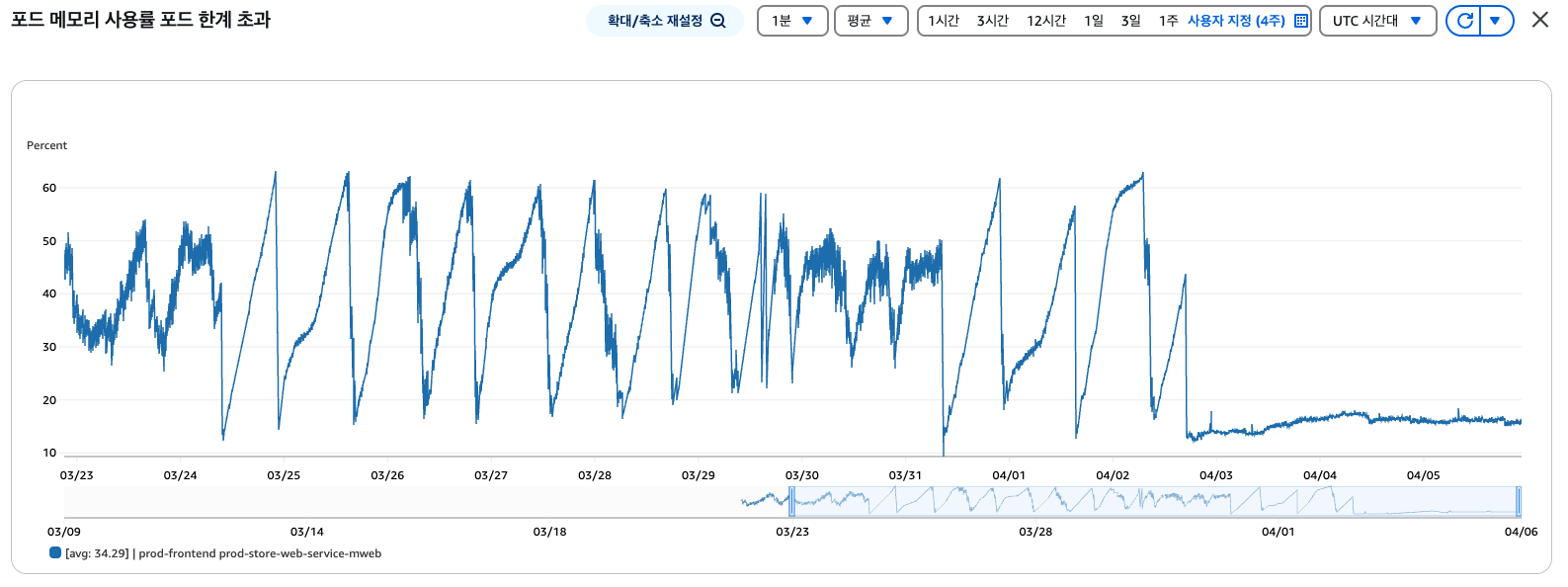
해결책
- Production 환경의 SSR 구간에서 Sentry 우선 제외 후 PJ 환경에서 Sentry 구성 변경 테스트 진행.
- Figma 메타데이터가 들어가는 이유 및 해당 부서의 업무 프로세스 파악 및 개선.
- 해당 문자열이 DB에 저장되지 않도록 BE에서 Sanitation 적용.
결론 및 교훈
이번 메모리 누수 문제 해결 과정을 통해 얻은 주요 교훈은 다음과 같습니다:
-
아키텍처 설계 시 환경 특성 고려:
- VM 환경에 최적화된 아키텍처를 Kubernetes 환경에 그대로 적용하면 오버헤드가 발생할 수 있습니다.
- 클라우드 네이티브 환경에서는 기존 방식을 재평가해야 할 필요가 있습니다.
-
SSR 구간에서의 로그 파악:
- SSR 구간에서 발생하는 Warning을 유심히 봐야 함.
- IDC - AWS간 대역폭이 모두 소진되었을 때 상품 상세가 원인이라는 것 까지는 인지했지만, 구체적으로 어떤 데이터가 들어가 있는지 자세히 보지 않았음. 데이터 크기가 비정상적으로 크다면 확인이 필요함.
-
메모리 모니터링 및 분석 체계화:
- 주기적인 메모리 사용량 모니터링으로 이상 징후를 조기에 발견할 수 있습니다.
- 코드 변경 이력과 메모리 사용량 변화를 연관 지어 분석하는 것이 중요합니다.
대규모 트래픽 환경에서 안정적인 서비스 운영을 위해서는 단순한 기능 구현뿐만 아니라, 시스템의 리소스 사용 패턴을 지속적으로 모니터링하고 최적화하는 것이 중요합니다. 이번 경험을 통해 프론트엔드 애플리케이션도 메모리 관리와 최적화가 중요한 요소임을 다시 한번 깨닫게 되었습니다.